![]()
FairML Datasets

![]()
A comprehensive Python package for loading, processing, and working with datasets used in fair classification.
Overview
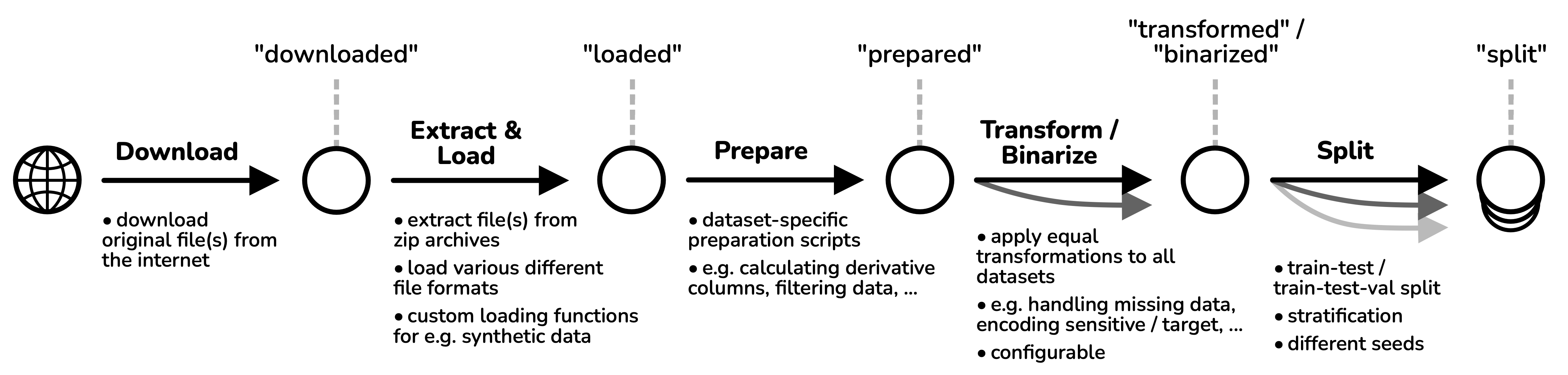
FairML Datasets provides tools and interfaces to download, load, transform, and analyze the datasets in the FairGround corpus. It handles sensitive attributes and facilitates fairness-aware machine learning experiments. The package supports the full data processing pipeline from downloading data all the way to splitting data for ML training.
Key Features
- 📦 Loading: Easily download, load and prepare any of the 44 supported datasets in the corpus.
- 🗂️ Collections: Conveneiently use any of our prespecified collections which have been developed to maximize diversity in algorithmic performance.
- 🔄 Multi-Dataset Support: Easily evaluate your algorithm on one scenario, five or fourty using a simple loop.
- ⚙️ Processing: Automatically apply dataset (pre)processing with configurable choices and defaults available.
- 📊 Metadata Generation: Automatically calculate rich metadata features for datasets.
- 💻 Command-line Interface: Access common operations without writing code.
Installation
Or using uv:
Quick Start
from fairml_datasets import Dataset
# Access a specific dataset by ID directly
dataset = Dataset.from_id("folktables_acsincome_small")
# Load the dataset
df = dataset.load()
# Check sensitive attributes
print(f"Sensitive columns: {dataset.sensitive_columns}")
# Transform the dataset
df_transformed, info = dataset.transform(df)
# Create train/test/validation split
df_train, df_test, df_val = dataset.train_test_val_split(df_transformed)
Are you curious which datasets are available? Check out the Datasets Overview in the side bar to see the list!
Command-line Usage
The package provides a command-line interface for common operations:
# Generate and export metadata
python -m fairml_datasets metadata
# Export datasets in various processing stages
python -m fairml_datasets export-datasets --stage prepared
# Export dataset citations in BibTeX format
python -m fairml_datasets export-citations
Terms of Use
FairGround is intended for fair ML research and promotes the ethical use of datasets. In line with this mission, we ask that you adhere to the following guidelines when using the package:
- Licenses. While FairGround itself is licensed permissively, the datasets within the corpus differ in their respective licenses (see “License” section). It is important to examine and comply with the respective licenses of the different datasets.
- Privacy. When using FairGround you agree to respect the data subjects’ privacy and not to try and re-identify any individuals within the datasets.
- Credit. Accurately credit / cite the datasets that you use, especially so in cases where a license mandates this e.g. via the Creative Commons BY clause. Please also properly credit FairGround if you use the package or corpus.
- Problematic datasets. FairGround explicitly adds warnings for all (to the best of our knowledge) datasets which have known issues. These datasets are largely included for comparability with prior work and we recommend against usage of these datasets unless it is important or required for a particular use case.
- Usage. Datasets in this package contain known biases that may lead to discriminatory outcomes if used without care. FairGround is intended for research and educational use, particularly to study and compare fair ML algorithms. Do not develop or deploy real-world models using these datasets without appropriate fairness evaluations, bias mitigation, and ethical consideration.
License
Due to restrictions in some of the third-party code we include, this work is licensed under two licenses.
The primary license of this work is Creative Commons Attribution 4.0 International License (CC BY 4.0). This license applies to all assets generated by the authors of this work. It does NOT apply to the generate_synthetic_data.py script, which instead is licensed under GNU GPLv3.
The second license, which applies to the complete repository, is the more restrictive GNU GENERAL PUBLIC LICENSE 3 (GNU GPLv3).
Please note that this licensing information only refers to the code, annotations and generated metadata. Individual datasets which are loaded and exported by this package may have different licenses. Please refer to individual datasets and their sources for dataset-level information.